
Kaggle: Microsoft Malware Detection
Problem statement
To detect what type of malware is present in the file
Data Source
For every malware, we have two files
- .asm file
- .bytes file (the raw data contains the hexadecimal representation of the file’s binary content, without the PE header)
Total train dataset consist of 200GB data out of which 50Gb of data is .bytes files and 150GB of data is .asm files:
There are total 10,868 .bytes files and 10,868 asm files total 21,736 files
There are 9 types of malwares (9 classes) in our give data -
- Ramnit
- Lollipop
- Kelihos_ver3
- Vundo
- Simda
- Tracur
- Kelihos_ver1
- Obfuscator.ACY
- Gatak
Mapping to a ML problem
There are 9 classes under target variable hence a multi-class classfication problem with metric to be used a log-loss metric.
Exploratory Data Analysis
First of all, we separate both file types into different folders.
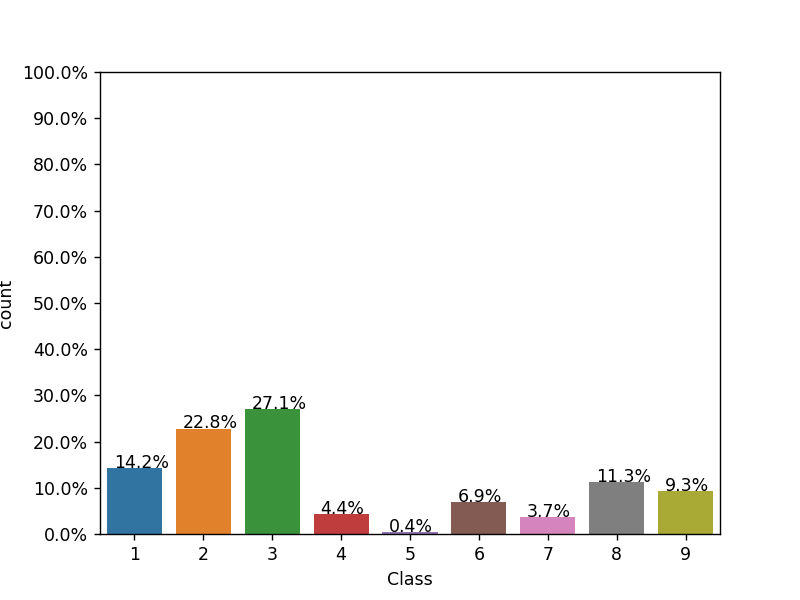
Distribution of malware classes
In whole data set
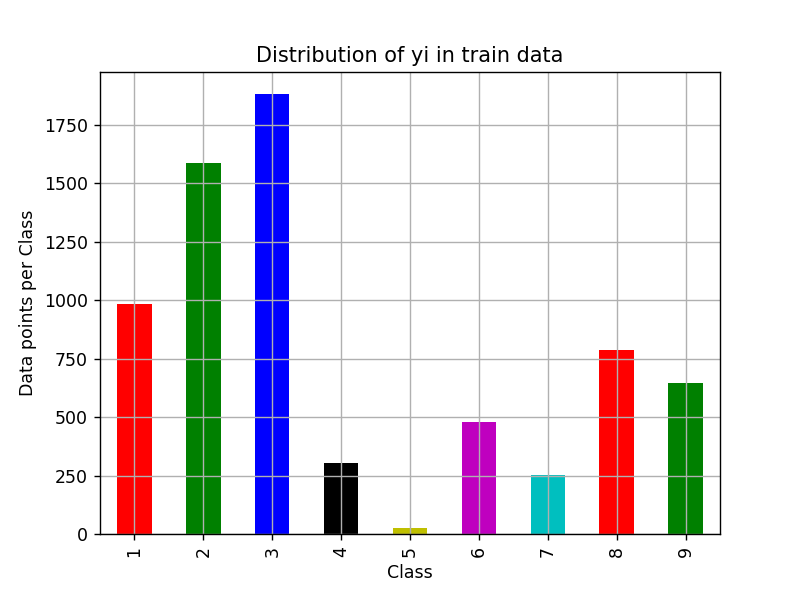
In train data set
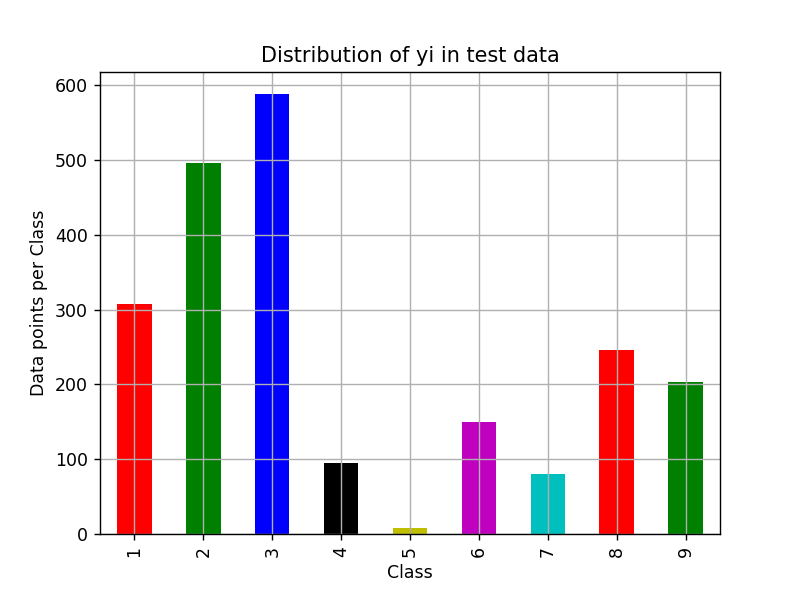
In test data set
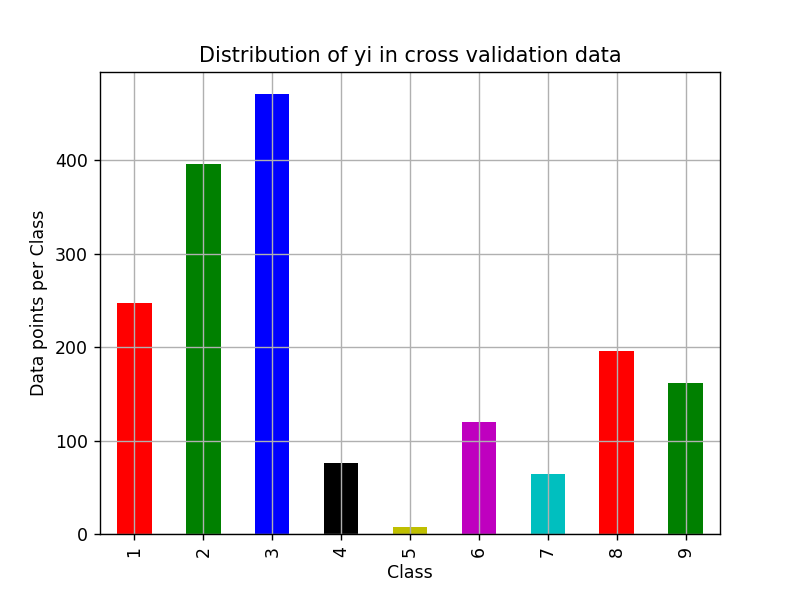
In validation data set
Feature Extraction
- Bytes file: A simple byte file has a representation as follows:
00401000 56 8D 44 24 08 50 8B F1 E8 1C 1B 00 00 C7 06 08
So, the first feature is to account for each byte file size, next we remove the address from each byte file (in above sample, address is 00401000) and create a unigram bag of words resulting into another 257 new features.
- asm file:
The assembly files consists of content which can be made of -
- Address
- Segments
- Opcodes
- Registers
- function calls
- APIs
Since given data size is 150GB, so we went through given discussion on Kaggle to choose 52 major commands (like push, pop, etc) and created unigram bag of words.
So finally we have nearly 300 features to be used in ML model.
Machine Learning modeling
Using parallel processing, we implemented following classifiers -
| Classifier | Train Log-loss | Validation Log-Loss | Test Log-Loss |
|---|---|---|---|
| RF | 0.016 | 0.016 | 0.040 |
| XG Boost | 0.011 | 0.031 | 0.032 |
| Tuned XG Boost | 0.012 | 0.034 | 0.031 |