
Kaggle: Netflix movie rating recommendation system
Problem statement
Predict the rating that a user would give to a movie that he has not yet rated.
Data sources
Get the data from Kaggle and convert all 4 files into a CSV file having features:
- Movie ID
- User ID
- Date (on which user gave rating)
- Rating (on a scale of 5)
Exploratory Data Analysis
With analysis, we see that there is no missing and no duplicate data.
Checking on unique entities:
- Total no of unique ratings : 100480507
- Total No of unique Users : 480189
- Total No of unique movies : 17770
After Train(80%):Test(20%) data split, we perform below operations.
Distribution of rating

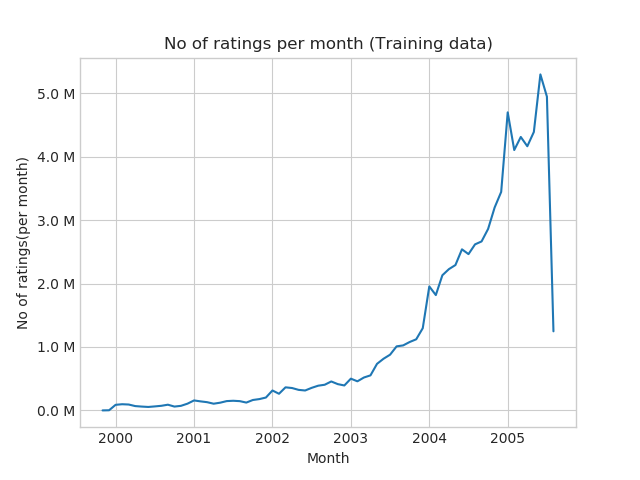
Number of ratings per month
Distribution of ratings given by users
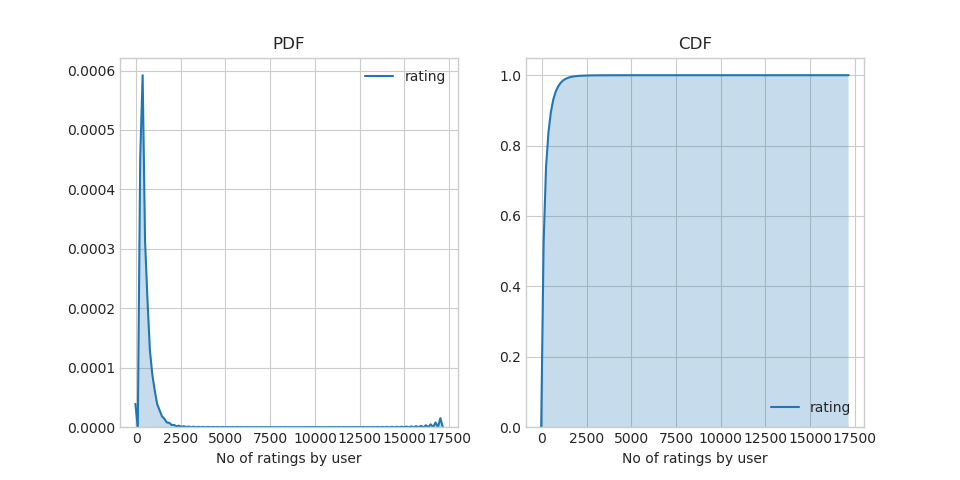
Majority of users are giving very less number of ratings as cleared from the right skewed PDF.
Distribution of ratings grouped by movies

Many (Popular) movies are getting large number of ratings as compared to other movies.
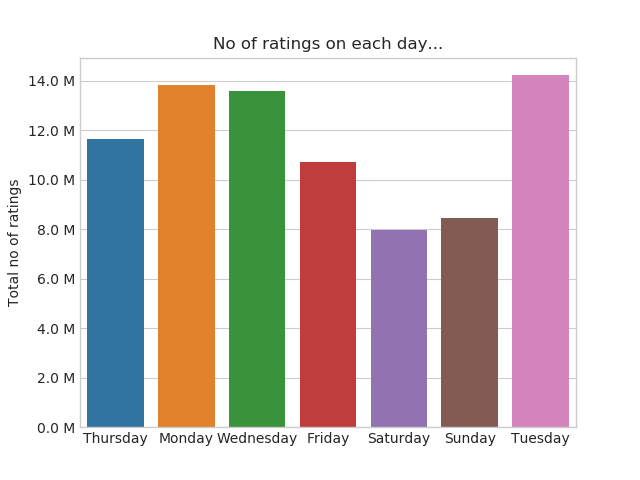
Number of ratings on each day
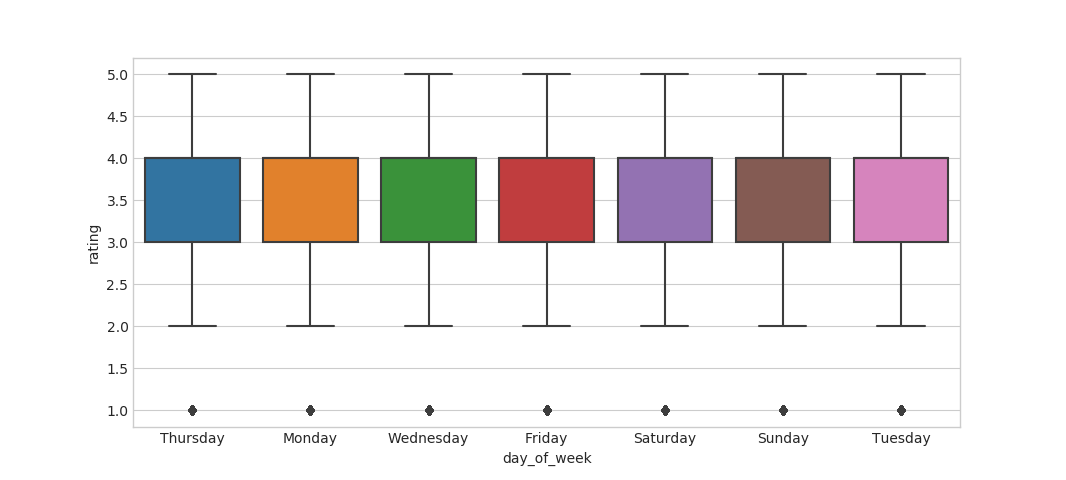
Constructing a compressed sparse matrix to form user-user similarity matrix and movie-movie similarity matrix
A compressed sparse row matrix with user ID (~480K) as index and movie ID (~17K) as features.
Now, constructing a user-user similarity matrix which is computed by taking cosine similarity of one user vector against all, resulting into a desnse matrix of size ~480K x ~480K dimension. Similarly, movie-movie similarity dense matrix of dimension ~17K x ~17K can be constructed.
Since the above size is too large for a normal computer to process, hence we took a sample of compressed sparse matrix to achieve the same.
Feature extraction
We know that as an input we will receive (user ID, movie ID) against which we need to predict the rating the user will give to given movie.
So, we can first construct three features as -
- Global Average - The total average of all the movie ratings
- User Average - The total average of ratings given by that user to all the movies
- Movie Average - The total average of ratings given by all users belonging to the target movie.
- Top 5 similar users - Next 5 features are built based on the top most 5 similar users to target user who have also watched the target movie.
- Top 5 movies watched by user - Finding top 5 similar movies to target movie and getting the rating given by target user. If among top 5 movies, user has not given rating to let’s say 4th movie, then top 6 movies similar are considered ignoring the 4th, in total keeping only 5 movies.
Therefore, we have a total of 13 features to build our ML models.
Machine Learning model
We implemented XG Boost model on given features resulting into a RMSE of 1.07
